ADF High-Level Structure
The following figure illustrates the high-level structure of the Allotrope Data Format (ADF) API stack:
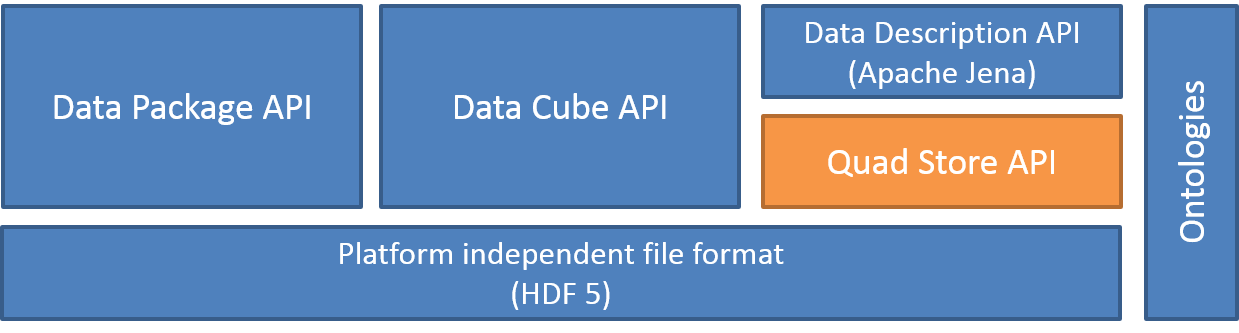
This document focuses on the ADF Quad Store implementation.
The Allotrope Data Format (ADF) [[!ADF]] consists of several APIs and taxonomies. The ADF Quad Store (ADF-QS) provides an efficient persistence layer for the RDF Data Model based on HDF5 [[!HDF5]]. It allows to store, query and retrieve RDF Statements in the RDF Data Model. The ADF Data Description API [[!ADF-DD]] uses the ADF Quad Store as backend, for example for metadata of Data Package elements, Data Cubes, experimental or process description and contextual metadata.
THESE MATERIALS ARE PROVIDED "AS IS" AND ALLOTROPE EXPRESSLY DISCLAIMS ALL WARRANTIES, EXPRESS, IMPLIED OR STATUTORY, INCLUDING, WITHOUT LIMITATION, THE WARRANTIES OF NON-INFRINGEMENT, TITLE, MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE.
This document is part of a set of specifications on the Allotrope Data Format [[!ADF]]
The ADF Quad Store (ADF-QS) provides an efficient persistence layer for the RDF Data Model based on HDF5 [[!HDF5]]. It allows to store, query and retrieve RDF Statements in the RDF Data Model. The ADF Data Description API uses the ADF Quad Store as backend, for example for metadata of Data Package elements, Data Cubes, experimental or process description and contextual metadata.
The document is structured as follows: In the following the requirements, architecture and technical realization of the quad store are described before the integration into the ADF API is briefly described.
Within this specification, the following namespace prefix bindings are used:
| Prefix | Namespace |
|---|---|
| owl: | http://www.w3.org/2002/07/owl# |
| rdf: | http://www.w3.org/1999/02/22-rdf-syntax-ns# |
| rdfs: | http://www.w3.org/2000/01/rdf-schema# |
| xsd: | http://www.w3.org/2001/XMLSchema# |
| dct: | http://purl.org/dc/terms/ |
| skos: | http://www.w3.org/2004/02/skos/core# |
| qb: | http://purl.org/linked-data/cube# |
| adf-dp: | http://purl.allotrope.org/ontologies/datapackage# |
| adf-dc: | http://purl.allotrope.org/ontologies/datacube# |
| adf-dc-hdf: | http://purl.allotrope.org/ontologies/datacube-to-hdf5-map# |
Within this document, decimal numbers will use a dot "." as the decimal mark.
The following figure illustrates the high-level structure of the Allotrope Data Format (ADF) API stack:
This document focuses on the ADF Quad Store implementation.
The ADF Quad Store MUST provide an efficient persistence layer for the RDF Data Model based on HDF5 [[!HDF5]].
The following picture describes the high-level structure of the HDF5 based ADF Quad Store:
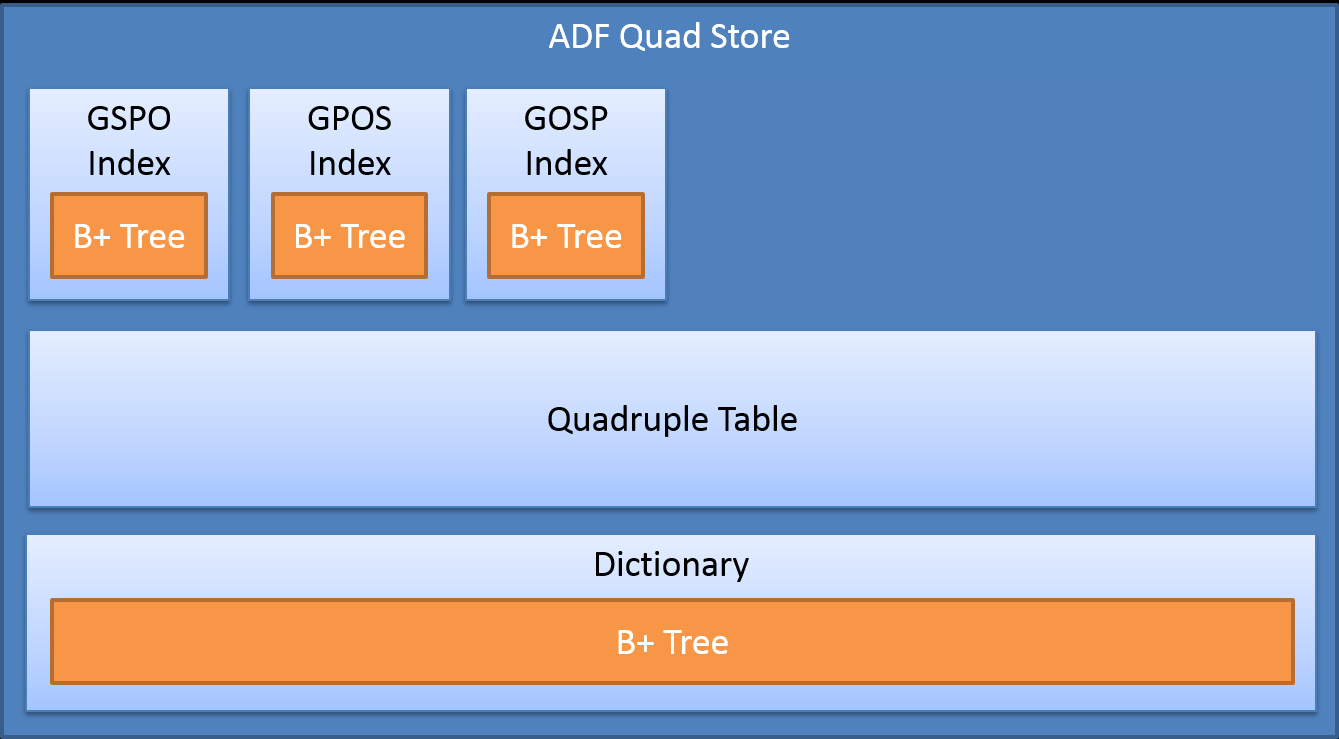
The Dictionary MUST contain the string representation of resources and literals and MUST provide efficient access to them.
The Quad Table represents the quads. It MUST consist of five columns - one for the graph, one for the subject, one for the predicate, one for the object of a quad and one to mark the quad as deleted. One row in the table represents one quad.
The ADF Quad Store MAY use different kinds of indices in order to improve the performance of basic operations such as inserting and querying of quads (triples into a specific graph), e.g. an GSPO index. The reference implementation uses three indices: GSPO, GPOS and GOSP. Three additional indices (SPOG, POSG and OSPG) are supported, but the current implementation would not benefit from them.
In order to provide efficient dictionaries and indexing to the ADF Quad Store, ADF-QS MUST store data in a B+ Tree data structure. In the implementation, one node in the B+ Tree MUST correspond to one row in the HDF5 Dataset that is represented by the tree.
The physical representation of the quad store in HDF5 consists of the elements described in the previous section. In the next subsections these elements are described in detail.
All HDF5 elements of the quad store (Groups and Datasets) MUST be located below the data-description Group.
The quads MUST be stored as their node IDs in an HDF5 Dataset [[!HDF5]]. The name of the Dataset MUST be quads and it MUST be located directly in the data-description Group.
This Dataset MUST have five columns - four for the node IDs and a fifth for the time of deletion of this quad. The Dataset MUST have the attributes nextID and size of type int containing the index of the next row to be used for a new quad and the current number of not-deleted entries.
A node ID is a 64 bit value with the following bit usage:
| Position | Length (in bit) | Description |
|---|---|---|
| 0 to 30 | 31 | A positive integer. ID of the nodes value string. |
| 31 to 62 | 31 | A positive integer. ID of the nodes namespace (resource), value type (literal) string or the language tag (string with language). |
| 62 to 63 | 2 | Flag representing the node type. 00: Blank node, 01: Resource node, 10: Literal node, 11: not used |
The ADF-TS MUST support the removal of statements. "Removal" here means that the statements are marked as deleted, but not actually physically removed. The idea is to keep the "removed" statements for an audit trail. To mark a quad as deleted the deletion time (in milliseconds since 1970-01-01 00:00:00) MUST be written to the fifth column of the quad Dataset.
A quad node may consist of two strings (value and namespace, type or language). Those strings MUST be stored and accessible via a dictionary structure. The dictionary MUST consist of a part responsible for the string storage and a B+ tree for fast access. All Datasets used by the dictionary MUST be located in the Group dictionary below the Group data-description.
The B+ tree uses the string itself as the key and the technical string ID as value. On B+ tree Dataset level these are the same values since the key entry in the nodes Dataset is the ID of the key (see section B+ Tree).
The strings MUST be persisted as bytes, using UTF-8. A one dimensional HDF5 Dataset contains a continuous byte stream. A two dimensional Dataset stores position and length in the byte stream or strings up to 12 bytes length. The row ID in the second Dataset is the technical ID of the string (used as part of the quad node ID and in the dictionary B+ tree). Both Datasets MUST have an attribute nextID of type int containing the index of the next row to be used for a new entry. The following two modes of storage for those bytes MUST be supported.
All data is stored in the 2D Dataset. Bytes 0 up to 11 contain the bytes of the string (starting at byte 0), byte 12 contains the number of used bytes.
| Position | Length (in byte) | Description |
|---|---|---|
| 0 to 11 | 12 | Byte representation of the string. |
| 12 | 1 | Number of bytes used for the string. |
The bytes of the string are stored in the 1D byte stream Dataset. Position and number of bytes in the stream are stored in bytes 0 to 11 of the 2D Dataset. Byte 12 is set to -1.
| Position | Length (in byte) | Description |
|---|---|---|
| 0 to 7 | 8 | A 64-bit long value. Field ID/position of the string in the byte stream dataset. |
| 8 to 11 | 4 | A 32-bit long integer value. Number of bytes of the string in the byte stream dataset. |
| 12 | 1 | Contains the value -1. |
The HDF5 based quad store implementation MUST use B+ trees stored in HDF5 Datasets. See [[!WIKI-BP-TREE]] for terminology and functional implementation details.
The nodes of the B+ tree MUST be stored in a two dimensional Dataset with data type int. The Dataset MUST have an attribute nextID of type int containing the index of the next row to be used for a new node. The number of columns MUST be two times the tree order plus one (2 * order + 1).
Field usage:
| Position | Count | Description |
|---|---|---|
| 0 to (order - 2) | order - 1 | IDs of the keys (or the keys if the key type is int), -1 for unused fields |
| (order - 1) to (2 * order - 2) | order | Inner node: IDs of the child nodes, 0 for unused fields Leaf node: IDs of the values (or the values if the value type is int), 0 for unused fields.Since it is not needed in leaf nodes, the last field there contains the ID of the right sibling node. This produces a ordered linked-list of all key-value pairs. |
| 2 * order - 1 | 1 | ID of the parent node (-1 on the root node) |
| 2 * order | 1 | Flags |
Flags:
| Position | Length (in bit) | Description |
|---|---|---|
| 0 | 1 | 0: Inner node, 1: Leaf node |
| 1 to 31 | 31 | not used |
In contrast to the common B+ tree implementation with the HDF5 based implementation the root node MUST remain in row 0 and so MUST keep ID 0.
An HDF5 based implementation SHOULD use an SPO, a POS and an OSP index as described below.
It MAY use additional indexes.
It MUST delete any index present that it does not update, when changing the content of the quad store.
Indices MUST be based on B+ trees.
The B+ tree Dataset MUST be located in a Group named index_>index name< below the data-description Group.
The default indices (GSPO, GPOS, GOSP, SPOG, POSG and OSPG) must use the quads Dataset entries as keys. These entries contain the node IDs of subject, predicate and object of the statement, and, if deleted, the deletion time, otherwise 0. The B+ tree values are the IDs of the quads Dataset entries. The name of the index defines the order for sorting those entries. The keys of an SPO index are sorted first by the subject node ID, then by the predicate node ID and last by the object node ID.
The following section describes the integration of the ADF Quad Store into the ADF API.
To use the ADF Quad Store in Jena, the Graph and TripleStore interfaces MUST be implemented.
For Graph the class GraphBase MUST be extended, which contains a lot of boilerplate code.
To use the ADF based graph an instance SHOULD be passed to Jena: ModelFactory.createModelForGraph(adfGraph).
| Version | Release Date | Remarks |
|---|---|---|
| 0.3.0 | 2015-04-30 |
|
| 0.4.0 | 2015-06-18 |
|
| 1.0.0 RC | 2015-09-17 |
|
| 1.0.0 | 2015-09-29 |
|
| 1.1.0 RC | 2016-03-11 |
|
| 1.1.0 RF | 2016-03-31 |
|
| 1.1.5 | 2016-05-13 |
|
| 1.2.0 Preview | 2016-09-23 |
|
| 1.2.0 RC | 2016-12-07 |
|
| 1.3.0 Preview | 2017-03-31 |
|
| 1.3.0 RF | 2017-06-30 |
|
| 1.4.3 RC | 2019-10-11 |
|
| 1.4.5 RF | 2018-12-19 |
|
| 1.5.0 RC | 2019-12-12 |
|
| 1.5.0 RF | 2020-03-03 |
|
| 1.5.3 RF | 2020-11-30 |
|